Des éditeurs de données sélectionnés, des nœuds et des développeurs de systèmes de gestion des collections obtiendront de petits contrats pour participer à un projet pilote qui explorera et affinera l'affichage de données de spécimens plus riches
Date limite : 2 octobre 2022
Le secrétariat du GBIF sollicite des propositions d'éditeurs de données, de nœuds de participants et de développeurs de systèmes de gestion des collections pour participer à un projet pilote montrant comment un modèle de données unifié émergent peut améliorer la manière dont les données dérivées de spécimens dans des collections scientifiques sont représentées dans le GBIF. Les détenteurs et les gestionnaires de données de spécimens choisis pour participer au projet pilote contribueront à faire progresser la capacité du modèle de données à prendre en charge des applications scientifiques plus larges des données de spécimens à l'avenir et à permettre la découverte d'enregistrements de spécimens au sein du Registre mondial des collections scientifiques (GRSciColl).
Le GBIF développe un nouveau modèle de données en réponse aux commentaires de la communauté et aux recommandations de l' examen de vingt ans du GBIF de CODATA pour permettre la publication de types de données sur la biodiversité plus riches et plus complexes à l'avenir. L'initiative a adopté une approche d'étude de cas, en commençant par des récits développés par des groupes d'éditeurs de données qui rencontrent actuellement des difficultés pour partager leurs données via le GBIF. L'analyse de ces études de cas a conduit à l'émergence d'un modèle de données unifié unique qui vise à satisfaire les exigences détaillées dans une collection croissante d'études de cas.
Le succès de ce travail dépendra de l'engagement d'un large éventail de personnes qui publient des données sur la biodiversité. Les personnes sélectionnées pour tester et affiner davantage le modèle unifié dans le cadre de cet appel à propositions prépareront des ensembles de données qui illustrent les complexités que les éditeurs de spécimens de données souhaitent capturer et partager via le GBIF à l'avenir. La série de webinaires communautaires en cours du GBIF continuera d'explorer, étude de cas par étude de cas, comment le modèle unifié proposé peut prendre en charge la structuration et la publication des données.
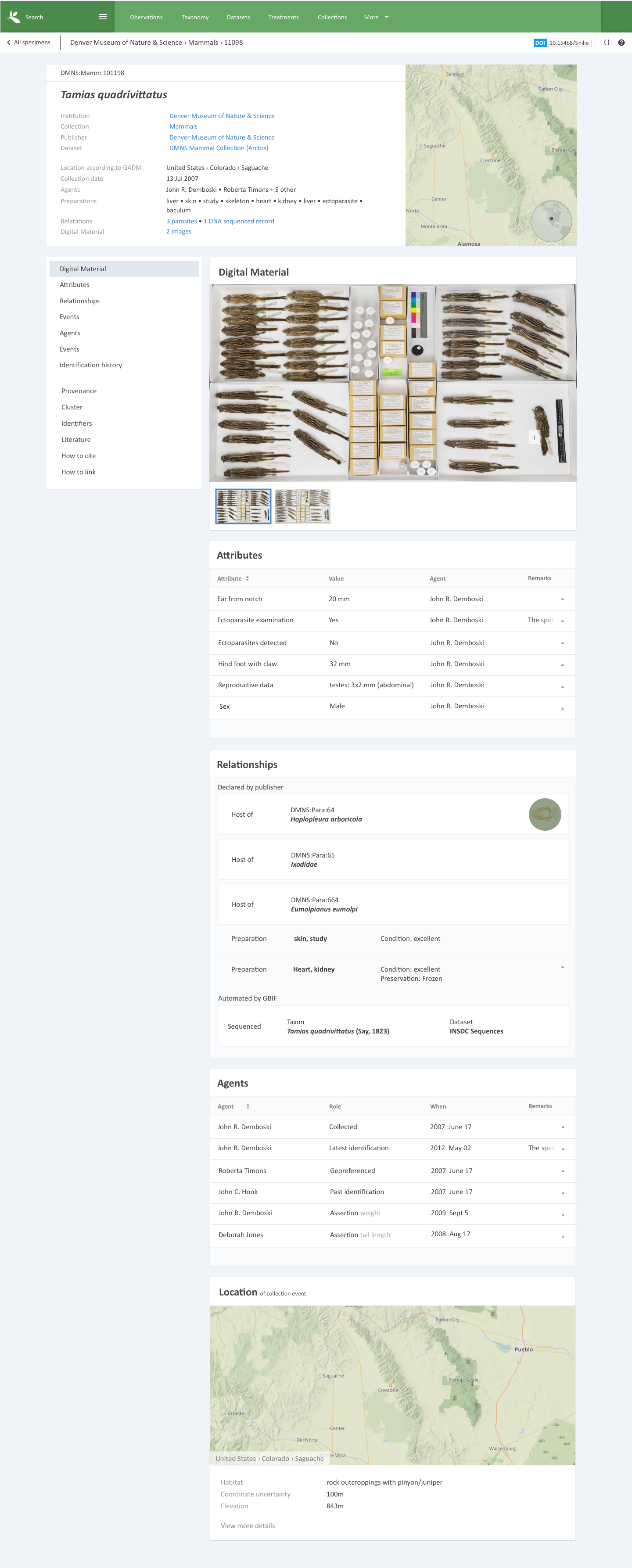
Le webinaire de juillet s'est concentré sur les systèmes de gestion des collections, utilisant des exemples de données d'Arctos pour démontrerune preuve de concept pour le modèle de données, tandis que d'autres membres du réseau GBIF qui travaillent avec des données relatives aux collections physiques et aux spécimens ont été invités à préparer des interventions et à offrir des commentaires. Ces contributions contribueront toutes au déploiement d'un catalogue de matériel qui explore des aspects plus riches des données de spécimens qui vont au-delà de la simple preuve spatio-temporelle physique des taxons actuellement détectables dans les occurrences basées sur des spécimens sur GBIF.org .
Un comité de sélection examinera les candidatures dont les résultats seront communiqués avant la fin octobre 2022. Les travaux sur le projet pilote commenceront en novembre 2022.
Portée du projet pilote
Les candidats sélectionnés dans le cadre de cet appel à propositions travailleront avec le Secrétariat pour remplir une base de données pilote utilisée pour démontrer un catalogue de spécimens en ligne interrogeable. L'objectif est de représenter fidèlement ces données à partir de leur source dans un environnement agrégé qui prend en charge une recherche et une enquête scientifiques plus larges que ce qui est actuellement possible. Le résultat du projet pilote présentera les données des candidats sélectionnés sur des pages modèles (Voir l'exemple).
Les candidats retenus devront accomplir les tâches suivantes sur une période d'environ six à huit semaines :
- Fournir un ou plusieurs ensembles de données reformatés dans le modèle de données unifié émergent sous forme de fichiers CSV adaptés à la base de données pilote
- Participer à des appels de groupe avec d'autres participants
- Fournir des commentaires et des suggestions sur l'affichage des données sur les pages de démonstration du catalogue de matériaux, y compris des sujets tels que :
- Comment les informations doivent être structurées et affichées
- Comment GBIF devrait appliquer des enrichissements, tels que des taxons supérieurs ou des informations géographiques, et les liens déduits vers d'autres éléments via nos algorithmes de clustering
- Comment le spécimen doit être cité, par exemple, en tant que matériel examiné dans un article
- Quels identifiants doivent être utilisés pour faire référence au spécimen et à la page du spécimen compilé (y compris éventuellement les DOI émis via le GBIF)
- Comment les annotations doivent être affichées, par exemple les drapeaux automatiques du traitement, l'utilisation future des annotations générées par la communauté
- Enregistrez une présentation et assistez à un webinaire communautaire pour partager et présenter vos propres données dans les résultats
Financement disponible et éligibilité pour postuler
Les candidats peuvent demander jusqu'à 3 000 € maximum pour soutenir leur participation à ce projet pilote sous la forme d'un petit contrat. Nous accueillons également les candidatures de groupes souhaitant autofinancer leur participation à ce projet pilote.
Les candidatures sont les bienvenues de la part des représentants, y compris du personnel ou des entrepreneurs individuels/indépendants de :
- Institutions situées dans un pays participant au GBIF (voir liste des pays participants votants et associés)
- Fournisseurs de systèmes de gestion des collections utilisés par les institutions dans les pays participant au GBIF
- Nœuds participants GBIF ayant une expérience de la mise en forme des données de collecte et qui ont accès aux données de collecte à utiliser dans ce projet pilote
- Partenariats entre l'un des éléments ci-dessus
Dans tous les cas, les candidats doivent démontrer dans leur proposition qu'ils sont autorisés à utiliser les données avec lesquelles ils ont l'intention de travailler au cours de ce projet pilote.
Tous les candidats doivent remplir l'un des critères suivants :
a) publier activement des données via le GBIF
b) s'engager à publier de nouveaux ensembles de données via le GBIF à la suite de ce travail
c) développer ou soutenir activement un système de gestion des collections et disposer d'un ensemble de données qui peut se conformer au critère a ou b
Les candidats doivent avoir de l'expérience et des connaissances dans les domaines suivants :
- Pratiques actuelles de publication des données du GBIF
- Structure des données qu'ils utiliseront dans le travail pilote
- Familiarité avec les objectifs du projet de diversification du modèle de données GBIF
- Compétence technique suffisante pour être en mesure de comprendre le modèle de données unifié et de fournir un ou plusieurs ensembles de données à l'aide de ce modèle. Un support technique sur le modèle unifié sera disponible pendant la durée du contrat, mais les candidats doivent être familiarisés avec les bases de l'utilisation d'une base de données telle que PostgreSQL, les schémas, les contraintes et les clés étrangères.
Processus et critères de sélection
Les candidatures seront évaluées par un comité de sélection, convoqué par le Secrétariat du GBIF, comprenant des experts externes, en utilisant les critères suivants :
- Historique de la publication régulière de données avec le GBIF et mise à jour des jeux de données publiés
- Maintenance des entrées GRSciColl associées
- Volume de données actuellement publiées dans le GBIF qui serait affecté, ou potentiel de combler les lacunes connues dans les données à l'avenir, à la suite de ce travail
- Expérience antérieure démontrée dans la publication de données plus complexes via GBIF (en ABCD ou en utilisant les extensions DwC-A)
- Étendue de l'ébauche du modèle de données qui sera couverte dans les données fournies pour ce projet pilote, par exemple (mais sans s'y limiter) :
- Mesures
- Media
- Identifications liées à l'ADN
- Plusieurs taxons dans les identifications
- Spécimens complexes
- Préparations de matériel
- Relations inter-échantillons
- Occurrences multiples d'individus biologiques spécifiques
- Liens entre collections
- Potentiel de réutilisation de la solution par d'autres éditeurs ; par exemple, des scripts réutilisables ou des améliorations à un outil que de nombreuses personnes utilisent
- Potentiel du projet pour accroître la diversité des collections couvertes par le projet de modèle de données GBIF et les régions géographiques des contributeurs
- Justification claire des coûts prévus associés à ce travail
Processus de demande
Les candidats doivent soumettre leurs propositions en anglais par e-mail avant le dimanche 2 octobre 2022.
Pour toutes les candidatures, veuillez préciser que le ou les dépositaires de données concernés soutiennent la candidature. Fournir des lettres de soutien si nécessaire.
Les candidats doivent fournir un document de proposition (deux pages maximum) comprenant :
- La personne de contact principale pour la candidature
- La personne ou l'institution qui recevra le contrat
- Tout autre partenaire qui serait impliqué dans les travaux du projet pilote soutenus par le contrat
- Une description de :
- Quels ensembles de données vous - ou vos partenaires - publiez actuellement des données via GBIF et quels défis avez-vous rencontrés pour adapter les données au modèle de données actuel ?
- Quel(s) ensemble(s) de données utiliseriez-vous dans ce projet pilote et quels domaines du nouveau modèle de données les données couvrent-elles ?
- Quels enregistrements GRSciColl se rapportent à l'application ?
- Comment le travail que vous entreprenez dans ce projet pilote pourrait-il être réutilisé par d'autres ?
- Comment le financement que vous demandez serait-il utilisé pour soutenir ce travail et prévoyez-vous d'apporter d'autres ressources en nature ?
Un comité de sélection examinera les candidatures dont les résultats seront communiqués avant la fin octobre 2022. Les travaux sur le projet pilote commenceront en novembre 2022.
Veuillez noter que les candidats retenus devront signer un contrat de service pour ce travail. Le paiement en euros suivra la réussite des tâches et un rapport narratif final..
Lire l'article original
{kind=link}
